
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 옵셔널 체이닝
- On-Premise
- elasticsearch
- vgw
- Custom Resource
- AWS
- 단축 평가
- 구조분해 할당
- Site-to-Site VPN
- docker swarm
- prometheus
- 온프레미스
- rust
- VPC
- 자바스크립트
- api gateway
- 비구조화 할당
- optional chaining
- grafana
- Proxy Resource
- docker
- cognito
- JavaScript
- 러스트
- transit gateway
- null 병합 연산자
- Service
- Kubernetes
- Await
- Endpoints
- Today
- Total
만자의 개발일지
[Java] StringTokenizer로 문자열에 있는 단어 개수 구하기 (백준 1152) 본문
StringTokenizer 클래스는 구분자를 기준으로 문자열을 나눠준다.
그렇게 나눠진 문자열을 token이라 부른다.
보통 문자열을 나눌때 많이 사용하는 방법이 String 클래스의 split()메소드를 사용하여 나누는 방법이다.
이 방법도 좋지만 그냥 엔터 혹은 스페이스만 입력했을 때 split()메소드가 무조건 배열을 리턴하기 때문에
배열의 길이가 1이 나오게 된다. 이럴때 StringTokenizer 클래스를 사용하게되면 손쉽게 해결할 수 있다.
StringTokenizer 클래스의 생성자는 3가지로 오버로딩 되어있는데
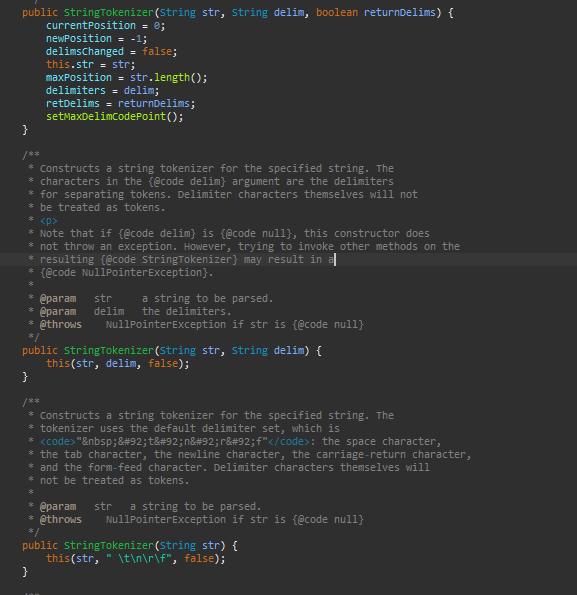
public StringTokenizer(String str, String delim, boolean returnDelims)
첫번째 매게변수인 String str은 문자열을 받고, 두번째 매게변수인 String delim은 구분자를 받는다.
세번째 매게변수인 returnDelims는 구분자도 token에 포함시킬지 말지 결정한다.
public StringTokenizer(String,str,String delim)
첫번째 매게변수로 문자열을 받고,두번째 매게변수로 구분자를 받는다.
public StringTokenizer(String str)
이 부분이 좀 신기했다.
구분자를 지정해 주지 않았을 때 공백 문자인 \t \n \r \f를 자동으로 구분 지어준다.
이제 사용해보도록 하자.
좋은 예시로 백준의 1152번 문제를 가져와 봤다.
문제를 보면 공백으로 단어의 개수를 구분한다고 나와있다.
그러면 아까 배웠던 StringTokenizer 클래스를 사용해보자.
import java.util.Scanner;
import java.util.StringTokenizer;
public class StringTokenizerExam {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
String string = scanner.nextLine();
StringTokenizer tokenizer = new StringTokenizer(string);
System.out.println(tokenizer.countTokens());
}
}Scanner 클래스로 문자열을 입력받고 String 변수에 담아서 StringTokenizer의 인자로 넘겨줬다.
구분자를 지정해주지 않았으니 모든 공백을 구분해준다.
StringTokenizer.countTokens() 메소드는 현재 가지고있는 토큰의 개수를 반환해준다.

테스트 케이스를 입력했을때 맞게 나오는 것을 볼 수 있다.
이부분까지는 split()메소드로도 충분히 할 수 있다.
하지만 많이들 틀리는 이유가 엔터 혹은 스페이스바를 입력했을때는 문자의개수가 0이 출력되어야 하는데 1이 출력되버리는 경우일 것이다.
import java.util.Scanner;
import java.util.StringTokenizer;
public class StringTokenizerExam {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in); //엔터 입력
String string = scanner.nextLine();
StringTokenizer tokenizer = new StringTokenizer(string);
System.out.println(string.split(" ").length);
System.out.println(tokenizer.countTokens());
}
}
split()의 구분자로 " "를 줬다.
엔터키를 입력했을때 두 방법의 차이를 비교해보자.

split() 사용한 방법은 1이 출력되고
StringTokenizer를 사용한 방법은 0이 출력되는것을 볼 수 있다.
split() 은 무조건 적으로 하나이상의 배열을 반환하기 때문에 1이 뜨는 것이다.
import java.util.Scanner;
import java.util.StringTokenizer;
public class BaekJoon1152 {
public static void main(String[] args) {
System.out.println(new StringTokenizer(new Scanner(System.in).nextLine()).countTokens());
}
}
짧게 쓰면 이런식으로 할 수 있다.