
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- transit gateway
- Service
- grafana
- elasticsearch
- null 병합 연산자
- On-Premise
- optional chaining
- Custom Resource
- 온프레미스
- 단축 평가
- docker swarm
- Kubernetes
- VPC
- 구조분해 할당
- JavaScript
- Await
- 러스트
- Endpoints
- rust
- docker
- vgw
- prometheus
- Proxy Resource
- Site-to-Site VPN
- 옵셔널 체이닝
- cognito
- api gateway
- 자바스크립트
- AWS
- 비구조화 할당
- Today
- Total
만자의 개발일지
[AWS] DynamoDB란 본문
DynamoDB
DynamoDB는 AWS에서 제공하는 서버리스 기반 Key-Value NoSQL 데이터베이스입니다.
DynamoDB를 사용하면 높은 성능과 비용적인 측면에서 이점을 가져올 수 있습니다.
DynamoDB 특징
- NoSQL 데이터베이스이다.
- NoSQL 데이터베이스에서는 JOIN이라는 개념이 없습니다. 애플리케이션 레벨에서 구현할 수는 있지만 매우 비효율적이며 NoSQL 데이터베이스를 쓰는 이유랑 맞지도 않습니다.
- JOIN이라는 개념이 없기 때문에 정규화도 거의 불가능합니다. 그래서 NoSQL에서는 보통 반정규화를 합니다.
- RDBMS(관계형 데이터베이스)는 종류나 특성에 따라 테이블을 나눴지만, DynamoDB에서는 모두 하나의 테이블에 표현할 수 있습니다.
- HTTP로 통신한다.
- DynamoDB는 HTTP로 통신합니다.
- 다른 DB 리소스들은 TCP Connection 기반인데 비해, DynamoDB는 Connectionless합니다.
- 서버리스(Serverless)이다.
- 서버리스이기에 DynamoDB를 위한 별도의 서버가 존재하지 않습니다. 따라서 요청한 만큼만 비용을 지불하면 됩니다.
- AWS Lambda 같은 다른 서버리스 기반 서비스와 좋은 시너지를 낼 수 있습니다.
- Key-Value 데이터베이스이다.
- Key를 제외한 테이블의 속성을 미리 정의해둘 필요가 없습니다.
- 따라서 데이터에 대해 미리 스키마가 만들어져 있어야 하는 RDBMS와 달리 DynamoDB는 유연하게 데이터를 처리할 수 있습니다.
DynamoDB 사용법
우선 DynamoDB 콘솔 화면으로 접속한 후 왼쪽에 Tables 메뉴를 선택합니다.
그다음 Create table 버튼을 눌러 바로 테이블 생성으로 넘어갑니다.
DynamoDB는 NoSQL이기 때문에 RDBMS와 같이 테이블이 데이터베이스에 종속되어있지 않습니다.

그다음 테이블 명을 지정해 준 후 파티션(Partition) 키와 정렬(Sort) 키를 지정해 주어야 합니다.
이번 포스팅에서는 파티션 키만 지정해 주도록 하겠습니다.

파티션 키와 정렬 키를 이해하기 위해서는 먼저 DynamoDB의 파티셔닝 원리를 이해해야 합니다.
DynamoDB 파티셔닝 원리

DynamoDB 내부에는 해쉬 함수(Hash Function)가 존재 합니다. 파티션 키는 이 해쉬 함수를 거쳐 데이터를 저장할 파티션을 결정하게 됩니다.
따라서 동일한 파티션 키를 지닌 데이터는 물리적으로 가까운 위치에 저장되게 됩니다. 이경우에 데이터를 구분하기 위하여 정렬 키를 사용합니다.
정렬 키를 사용하면 동일한 파티션에 저장된 데이터는 정렬 키를 기준으로 순서대로 저장되게 됩니다.
위 이미지에서 파티션 키는 AnimalType 이고 정렬 키는 Name 입니다.
보시다시피 파티션 키(AnimalType)가 동일한 데이터가 같은 파티션에 저장되는 것을 보실 수 있습니다.
그리고 같은 파티션에 저장된 데이터들은 정렬 키(Name)를 기준으로 순서대로 저장되는 것을 보실 수 있습니다.
위 내용을 정리하면 다음과 같습니다.
- DynamoDB 내부에 해쉬 함수가 존재합니다. 이 함수는 파티션 키를 입력받고 출력 값으로 데이터를 저장할 파티션을 결정합니다.
- 파티션 키(Partition Key)
- 파티션 키는 물리적인 공간인 파티션을 구분하기 위한 키입니다.
- 스케일이 아무리 커져도 주소를 알고 있어 데이터를 빠르게 가져올 수 있습니다.
- 때문에 파티션 키로는 일치하는 값만 가져올 수 있고, =, >, < 등과 같은 연산자를 사용하는 범위지정 방식의 검색은 지원하지 않습니다.
- 정렬 키(Sort Key)
- 정렬 키는 파티션 안에서 데이터를 정렬하기 위한 키입니다.
- DynamoDB에서는 Number, Binary, String 타입을 지원합니다. (String의 경우 utf-8을 기준으로 정렬됩니다.)
- 단순 정렬이기 때문에 파티션의 사이즈가 커져도 데이터를 빠르게 가져올 수 있습니다.
- 파티션키와는 달리 범위지정 방식의 검색을 지원합니다. 하지만 정렬 키만 가지고는 검색할 수 없습니다.
그다음 용량 모드(Capacity mode)와 보조 인덱스(Secondary index)를 지정해줘야 합니다.
우선 용량 모드는 온디맨드로 지정해주고, 보조 인덱스는 생성하지 않도록 하겠습니다.
각각이 무엇인지는 아래에서 설명하도록 하겠습니다.

DynamoDB 용량 모드
DynamoDB는 온디맨드와 프로비저닝 방식의 두 가지 용량 모드가 존재합니다.
- 온디맨드(On-demand)
- 온디맨드 방식은 사용한 만큼만 가격을 지불하는 방식입니다.
- 많은 트래픽이 발생할 수록 이전에 도달한 최대 트래픽 수준까지 확장됩니다.
- 만약 이전에 도달한 최대 트래픽을 넘는다면 이전의 2배에 해당하는 크기로 자동 조정됩니다.
- 프로비저닝(Provisioned)
- 프로비저닝 방식은 애플리케이션에 필요한 초당 읽기 및 쓰기 횟수를 지정합니다.
- 오토 스케일링을 사용하여 트래픽 변경에 따라 프로비저닝된 용량을 자동으로 조정할 수 있습니다.
- 따라서 프로비저닝된 모드를 사용하면 비용을 예측하는데 많은 도움이 됩니다.
DynamoDB Secondary Index(보조 인덱스)
아래 테이블에서 쿼리를 통해 "Toy Story"에 출연한 배우들의 데이터를 불러올 수 있을까요?
결론 부터 말하자면 불가능합니다.

정렬 키(Movie)의 값이 똑같다 한들 정렬 키가 속해있는 파티션 키가 다르기 때문에 정렬 키를 기준으로 데이터를 쿼리할 수 없습니다.
이러한 상황을 위해 DynamoDB는 보조 인덱스라는 기능을 제공합니다.
DynamoDB의 보조 인덱스에는 로컬 보조 인덱스(Local Secondary Index, LSI)와 글로벌 보조 인덱스(Global Secondary Index, GSI)가 있습니다.
로컬 보조 인덱스(Local Secondary Index, LSI)
로컬 보조 인덱스는 파티션 키는 동일하지만 정렬 키는 다른 인덱스입니다.
로컬 보조 인덱스는 동일한 파티션 키를 갖는 파티션으로 범위가 지정된다는 점에서 로컬입니다.
로컬 보조 인덱스는 다음과 같은 특징을 가지고 있습니다.
- 파티션 키는 테이블의 기본 키와 동일합니다.
- 정렬 키는 정확히 하나의 스칼라 속성(Number, String, Binary)으로 구성됩니다.
- 테이블의 기본 정렬 키가 인덱스로 프로젝션되며, 이 인덱스는 키가 아닌 속성으로 작동합니다.
- 테이블당 5개까지 생성 가능합니다.
- 테이블을 생성할 때 함께 생성해야 하며, 테이블이 생성된 이후에는 추가, 수정, 삭제가 불가능합니다,
글로벌 보조 인덱스(Global Secondary Index, GSI)
글로벌 보조 인덱스는 파티션 키와 정렬 키가 모두 다른 인덱스입니다.
글로벌 보조 인덱스는 모든 파티션에 걸쳐있을 수 있다는 점에서 글로벌입니다.
글로벌 보조 인덱스는 다음과 같은 특징을 가지고 있습니다.
- 테이블과 다른 파티션 키 및 정렬 키를 가질 수 있습니다.
- 정렬 키는 생략 가능합니다.
- 테이블당 20개까지 생성 가능합니다.
- 테이블 생성 후에도 생성할 수 있으며, 생성된 이후에도 추가, 수정, 삭제가 가능합니다.
그다음 Create table 버튼을 눌러 테이블을 생성해 줍니다.

테이블이 잘 생성된 것을 보실 수 있습니다.

이제 테이블에 데이터를 추가해보도록 하겠습니다.
위에서 생성한 테이블을 선택한 후 왼쪽 메뉴에 Explore items 메뉴를 선택해 줍니다.
그다음 Create item 버튼을 눌러 데이터를 추가해줍니다.

Add new attribute 버튼을 눌러 속성을 추가해 줍니다. 여기서 주의할 점은 DynamoDB의 예약어들은 테이블 속성명에 사용할 수 없습니다.
정확하게는 속성명을 예약어로 지정한 후 데이터를 추가해도 에러는 나지 않지만 나중에 쿼리할 때 문제가 발생할 수 있습니다. 때문에 속성명을 예약어로 사용하지 않는 것이 좋습니다.
다 지정해줬다면 Create item 버튼을 눌러 데이터를 추가해줍니다.

DynamoDB의 예약어는 아래 공식문서에서 확인하실 수 있습니다.
https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/ReservedWords.html
DynamoDB의 예약어 - Amazon DynamoDB
DynamoDB의 예약어 다음 키워드는 DynamoDB에서 사용하기 위해 예약되어 있습니다. 이러한 단어를 식에서 속성 이름으로 사용하지 마세요. 이 목록은 대/소문자를 구분하지 않습니다. DynamoDB 예약어
docs.aws.amazon.com
DynamoDB 테스트
DynamoDB를 테스트하기 위해 람다 함수를 만들고 AmazonDynamoDBFullAccess권한을 부여하였습니다. (람다 함수 생성은 생략하도록 하겠습니다.)
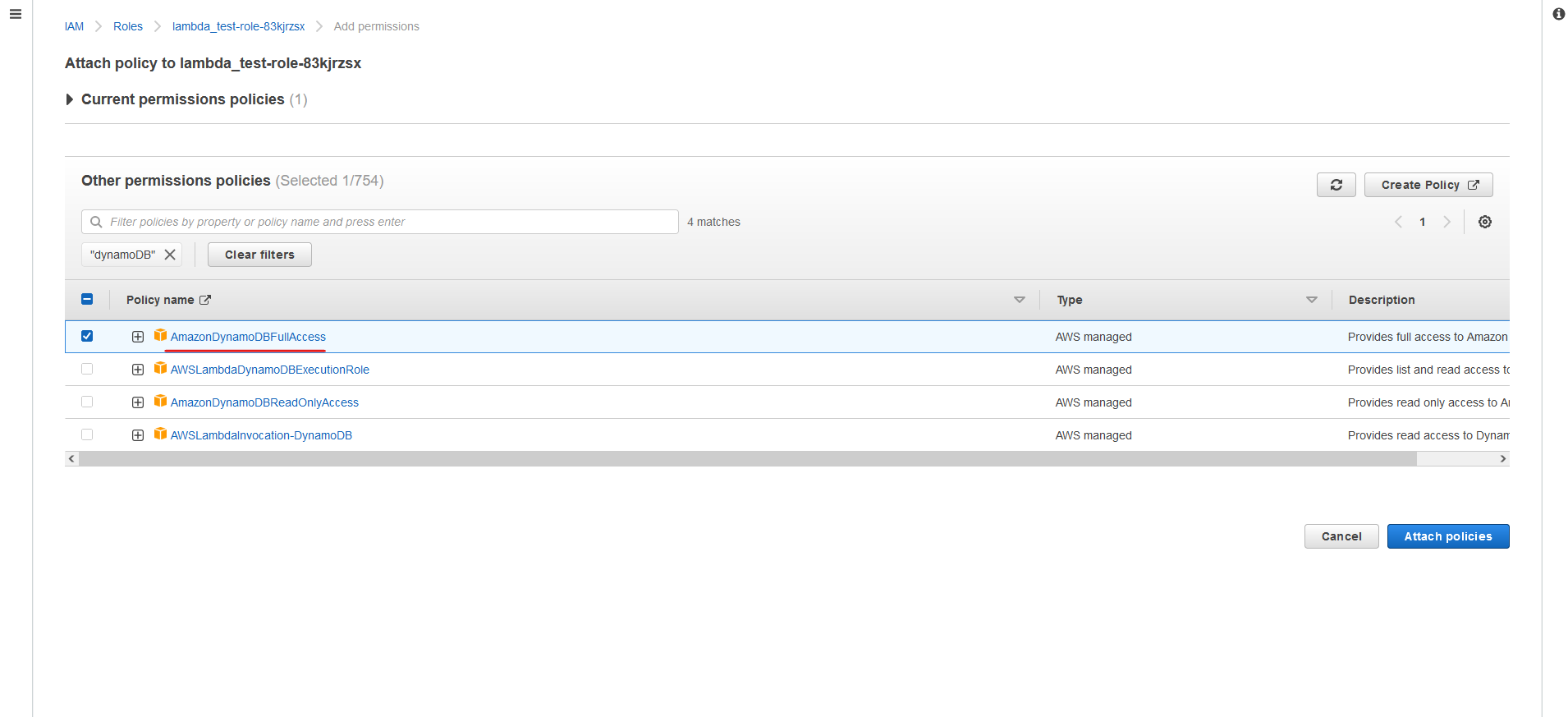
그다음 다음과 같이 람다 함수를 작성해줍니다. (Node.js를 사용하였습니다.)
const AWS = require("aws-sdk");
AWS.config.update({region: process.env.AWS_REGION});
const docClient = new AWS.DynamoDB.DocumentClient({apiVersion: '2012-08-10'});
exports.handler = async (event) => {
let params = {
"TableName": 'User',
"Key": {
"user_id": "dynamodbuser"
}
};
const data = await docClient.get(params).promise();
const response = {
statusCode: 200,
body: JSON.stringify(data)
};
return response;
};aws-sdk를 통해 user_id가 dynamodbuser인 데이터를 가져오는 예제입니다.
작성한 코드를 배포한 후 테스트를 진행해 줍니다.
DynamoDB에서 데이터를 잘 불러오는 것을 보실 수 있습니다.
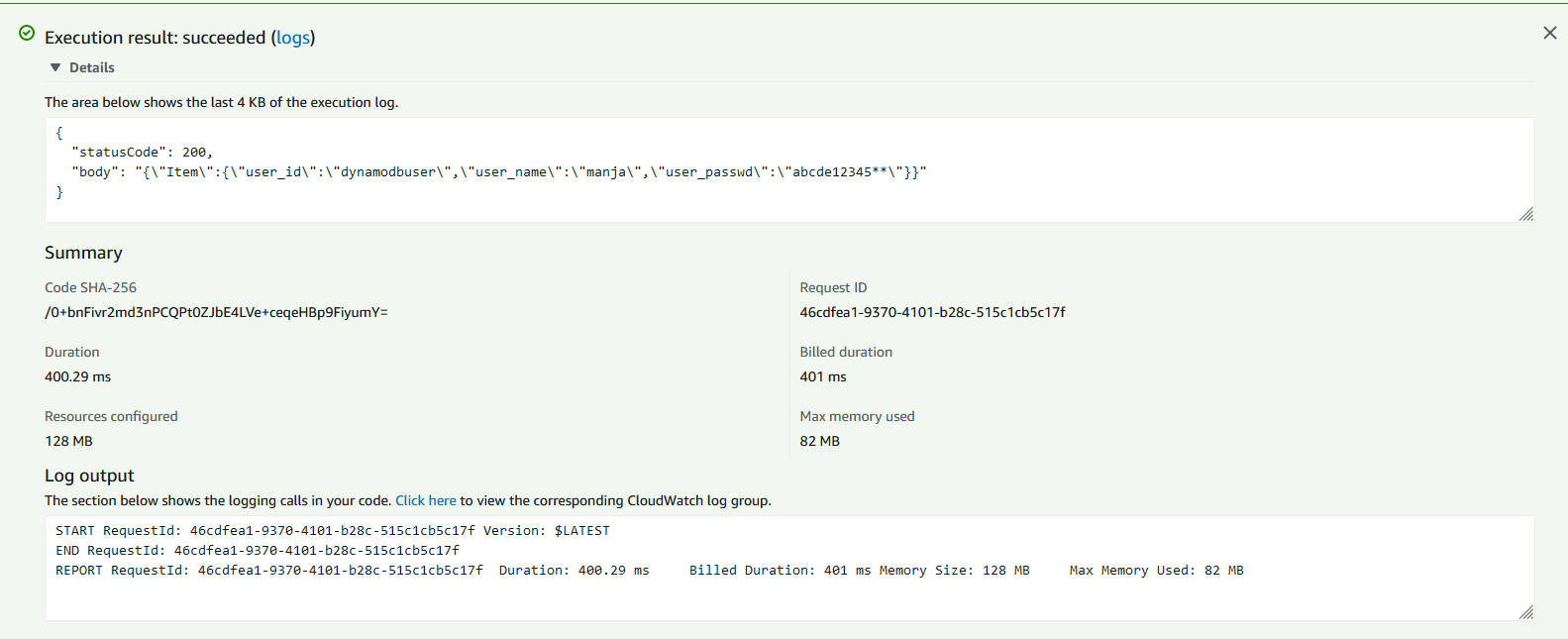
이처럼 DynamoDB를 사용하면 저렴한 가격으로 높은 성능의 데이터베이스를 사용하실 수 있습니다.
참고
- https://alphahackerhan.tistory.com/39
- https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/HowItWorks.Partitions.html
- https://ohgyun.com/805
- https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/HowItWorks.ReadWriteCapacityMode.html
- https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/GSI.html
- https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/LSI.html
'AWS' 카테고리의 다른 글
| [AWS] Cognito란 (0) | 2022.06.09 |
|---|---|
| [AWS] ALB 경로 기반 라우팅 구현하기 (2) | 2022.06.08 |
| [AWS] API Gateway Custom Resource 사용하기 (0) | 2022.05.19 |
| [AWS] API Gateway Proxy Resource 사용하기 (0) | 2022.05.18 |
| [AWS] VGW와 CGW를 사용하여 Site-to-Site VPN 구성하기 (0) | 2022.05.13 |



